Web Crawler
If you are looking for an alternative data source to integrate with Orama Cloud, you can use our Web Crawler to index the contents of your website. This is particularly useful when you want to index a public website that does not provide an API.
In order to use the Web Crawler, you need to be logged in to your Orama Cloud dashboard, and inside a project click on the Add index button, and then select the Web Crawler data source.
Usage
The Web Crawler data source allows you to index the contents of a website by providing the URL of the website you want to index. Once started, it will then crawl through the website links, index the contents of the pages, and make them available for search.
The Web Crawler can be configured to exclude certain URL paths from being indexed. This can be useful if you want to exclude certain parts of your website from being indexed, such as admin pages or pages with sensitive information.
Limitations
There are some limitations to the Web Crawler, such as the number of pages that can be indexed and the time it takes to index a website. If you have a large website with many pages, it may take some time for the Web Crawler to index all the pages.
More over, the Web Crawler may not be able to index all the pages of a website due to the website’s structure, non-standard HTML semantic, or other limitations like website configuration or robots.txt file.
Client side rendered websites, websites with dynamic content, or websites with complex JavaScript may not be fully indexed by the Web Crawler.
Creating an index
Create a new index in the dashboard by selecting the data source “Web Crawler”.
Insert an index name and your website homepage URL.
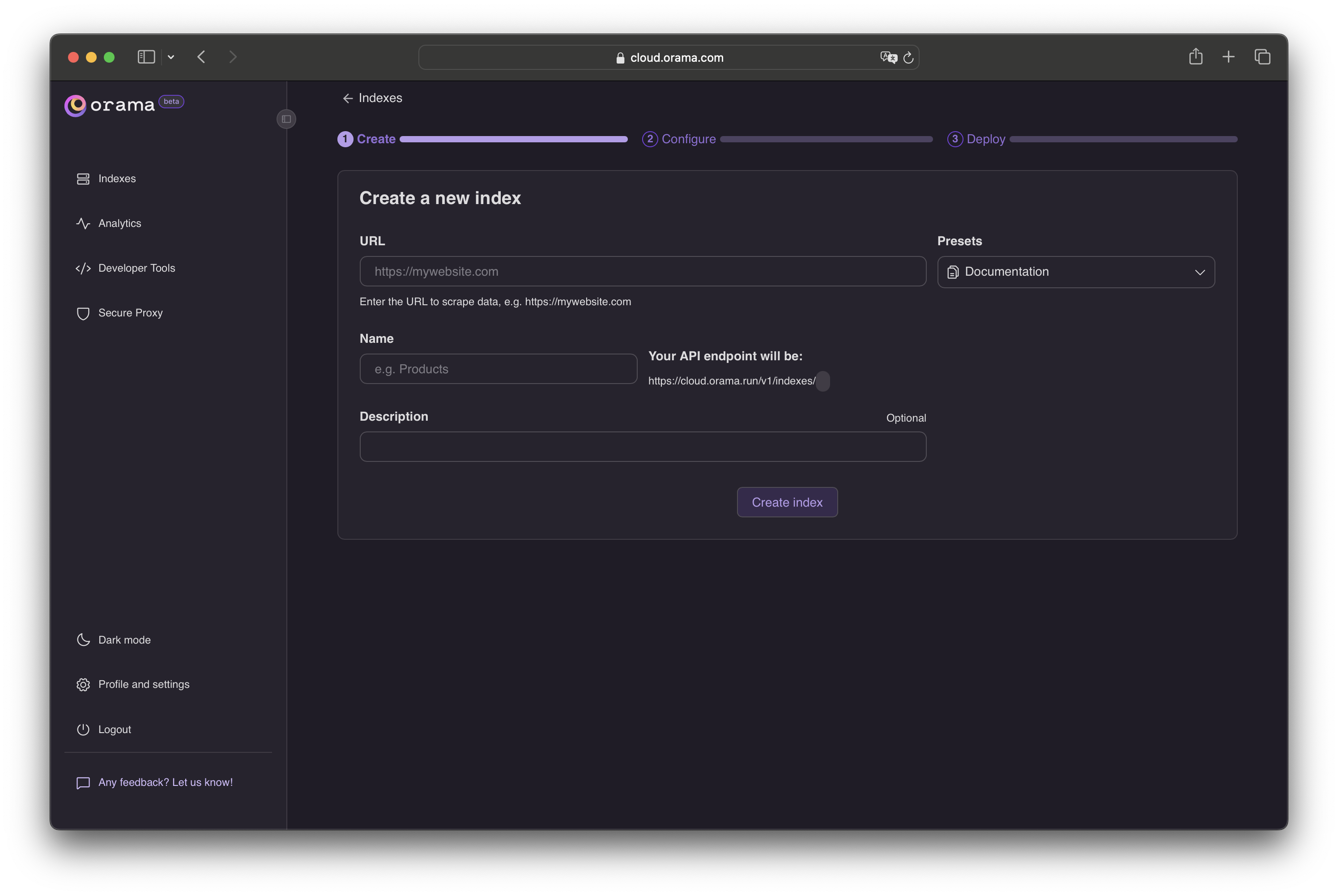
Click Create index and proceed to the crawler configuration.
In this section, you can optionally configure how the data should be scraped.
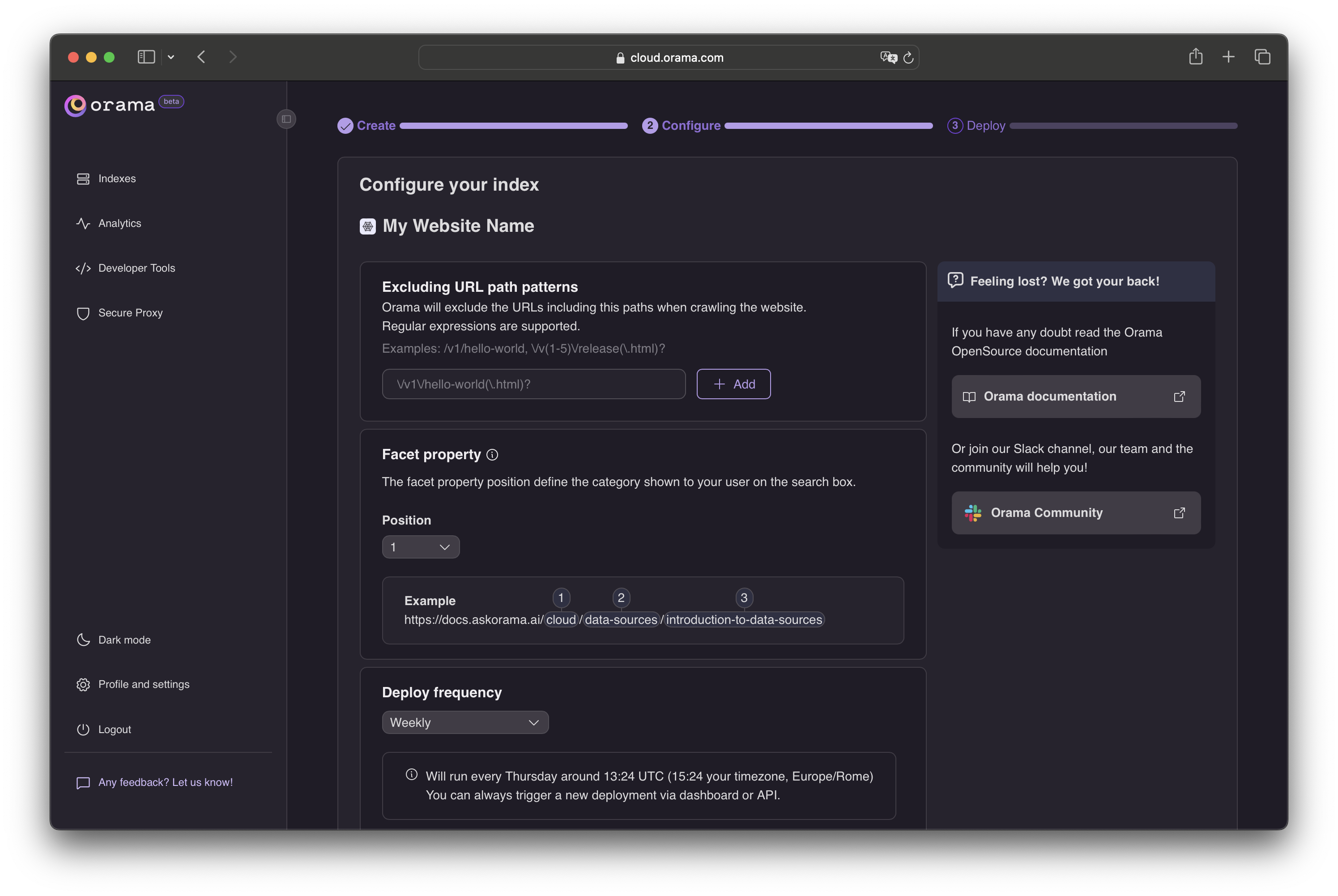
Excluding URL with path patterns:
you can exclude certain URLs from being indexed by providing a list of URL path patterns to exclude, using Regular Expressions.Facet property:
you can configure the facet property for the indexed pages, based on the URL structure, that can be used to categorize and filter your search documents.Deploy frequency:
Finally, you can set the deploy frequency to determine how often the Web Crawler should re-index your website.Click Save and Deploy and the Web Crawler will do the heavy lifting. It will crawl through your website links and index the contents of all the pages.
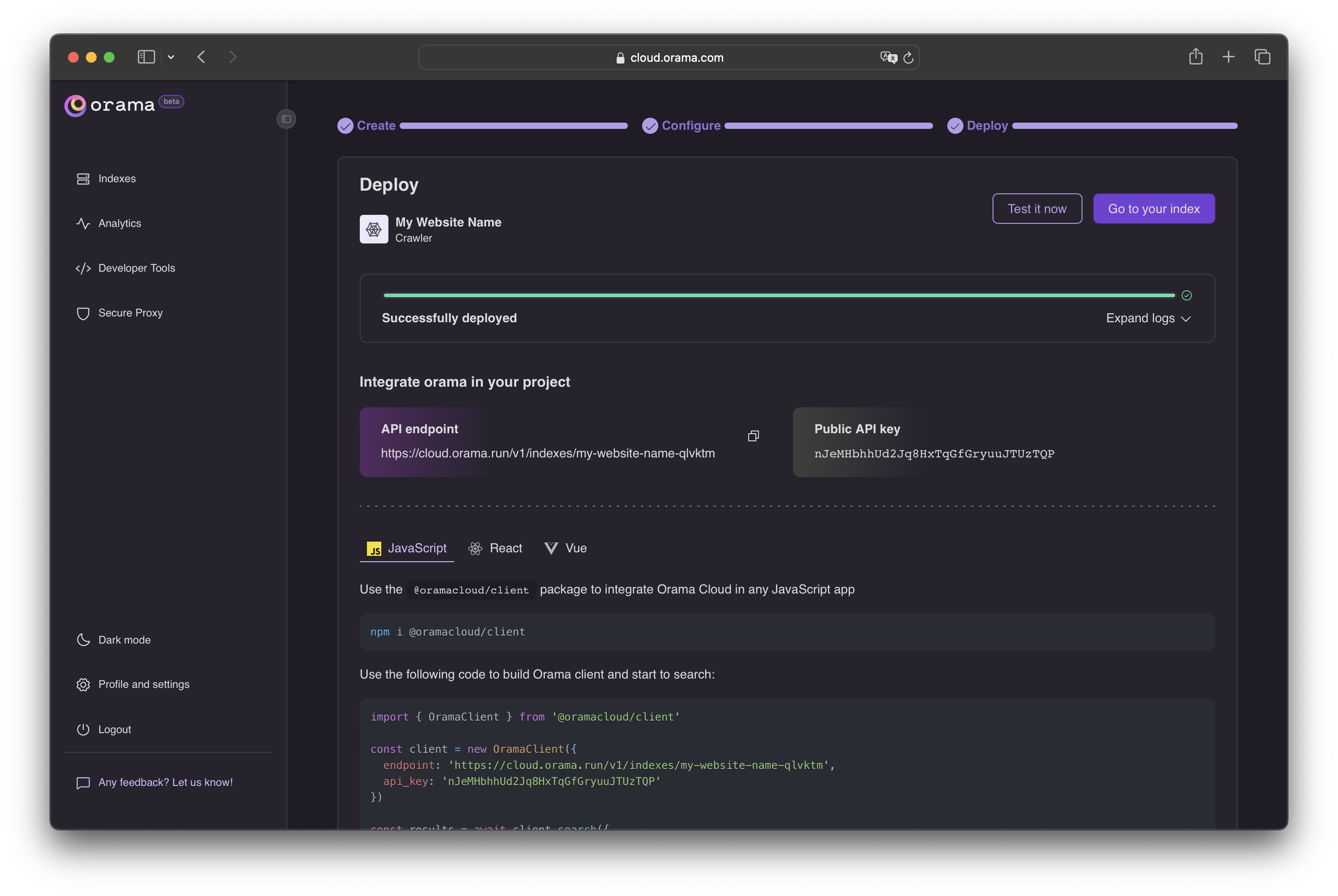
Done! 🎉 You just indexed your website data. If you want, you can test your index by clicking the Test now button.
Troubleshooting
Firstly, check out the logs displayed in the dashboard to see if there are any errors.
Verify that the website URL is correct and accessible. Also, make sure that the index configuration is correct, including the Excluding URL path patterns option. If you are unsure about the URL patterns to exclude, you can test them using a Regular Expression tester.
Large websites with many pages can take a long time to index. In some cases, the Web Crawler may not be able to index all the pages due to the website’s structure or limitations.
If you are still having trouble, please reach out to our Slack for support.
Integrating into your app
Now that you have your index deployed, you can start using it in your application's frontend.
You can install a ready-to-use Web Component to your site, like the Search Box, which is framework agnostic and can be used in any JavaScript environment.
You can also install the JavaScript SDK to build your own searching experience.